
Problem: Handwriting Recognition
Want to try solving this problem? You can submit your code online if you log in or register.
Handwriting Recognition
Input Files: handin.txt, symbols.txt,
dict.txt
Output File: handout.txt
Time Limit: 0.3 seconds
You are an employee of a new handheld computer company that is preparing its flagship product, the Assistant for Intelligent and Organised Computing. This product has so many bells and whistles that there is no room left for a keyboard. It is thus your task to implement handwriting recognition for this device.
Fortunately the device is not required to learn the handwriting style of its user. Instead the user must learn the single handwriting style recognised by the device. Every letter is represented as a sequence of up, down, left or right strokes. In order to enter a letter, the user must draw the appropriate sequence of strokes without taking their pen away from the drawing area.
As an example, the figure below illustrates the letters B, C, I and L, each drawn without taking the pen away from the drawing area. Below each of these letters is a simplified representation using only up, down, left and right strokes (although some strokes have been angled slightly so that they can be distinguished in the diagram). In each symbol the beginning of the pen movement is indicated by a black circle, and the direction of the pen movement is indicated by an arrow.
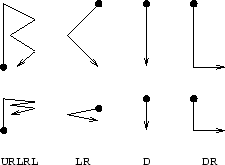
For this problem you are given a file symbols.txt listing every recognised letter and the corresponding sequences of up, down, left and right strokes.
Unfortunately, users are not precise and cannot draw accurate horizontal and vertical strokes. If a user draws a diagonal stroke, your program may interpret it as one of two types of stroke as follows.
- A stroke running diagonally up and to the left may be interpreted as an up stroke or as a left stroke;
- A stroke running diagonally down and to the left may be interpreted as a down stroke or as a left stroke;
- A stroke running diagonally up and to the right may be interpreted as an up stroke or as a right stroke;
- A stroke running diagonally down and to the right may be interpreted as a down stroke or as a right stroke.
As an example, consider the symbol entered by a user that is illustrated below. The first stroke may be interpreted as either a down stroke or a left stroke. The second stroke is precisely horizontal and so must be interpreted as a right stroke. Using the sequences for B, C, I and L described above, the symbol could thus represent either of the letters C or L.
In order to resolve such ambiguities, you must consider each letter within the larger context of a word. You are given a dictionary of recognised words in the file dict.txt, and you may assume that each word entered by a user belongs to this dictionary.
As an example, suppose that the only letters recognised are B, C, I and L (as described previously) and that the dictionary contains the word BIC but not BIL. Consider the word illustrated below.
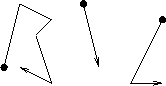
The first two symbols unambiguously represent B and I. The third symbol might represent either C or L as described above. However, since BIC belongs to the dictionary but BIL does not, your program can deduce that the word entered by the user is BIC.
Your task is to write a program that reads a number of words entered by a user, where each word is presented as a sequence of symbols. For each input word your program must output the corresponding dictionary word that is represented. You are guaranteed for each input word that there is one and only one dictionary word that it can represent.
Input
The input is contained in three files: symbols.txt, dict.txt and handin.txt.
The file symbols.txt will contain a list of individual letters that your program must understand and the corresponding sequences of up, down, left and right strokes. Each letter and its sequence of strokes will be described on a separate line. No letter will be described more than once. At least 1 and at most 26 letters will be described. Following these lines will be a single line containing a single hash character (#).
Each individual line (except for the line containing the hash character) will contain an upper-case letter to be recognised, followed by a single space and then a sequence of upper-case characters representing strokes. Up, down, left and right strokes will be represented by the characters U, D, L and R respectively. Each line will contain at least 1 and at most 6 strokes.
The file dict.txt will contain a dictionary of recognised words. This dictionary will be presented as a series of lines each containing a single upper-case word. Each word in the dictionary will be at least 1 letter and at most 50 letters long. The dictionary will contain at least 1 and at most 1000 words. No word will be contained in the dictionary more than once. The list of words will be terminated by a line containing a single hash character (#).
The file handin.txt will contain a series of words entered by a user. At least 1 and at most 1000 words will be presented. Each word will be described using several lines as explained below. Following this series of words will be a line containing the single integer 0.
The first line of each word description will contain a single integer k representing the number of letters in the word. Following this will be k lines describing the k letters of the word in order from first to last. Each letter will be described as a symbol entered by the user.
Each line describing a symbol will begin with an integer s representing the number of strokes in the symbol (1 <= s <= 6). Following this will be a sequence of s+1 points (separated by spaces) giving, in order, the beginning of the first stroke, the end of the first stroke (which is also the beginning of the second stroke), the end of the second stroke and so on, finishing with the end of the last stroke. Each point is described by an integer x-coordinate followed by a single space then an integer y-coordinate, where larger values of x indicate points further to the right and larger values of y indicate points further upwards. Each coordinate will be between 0 and 100 inclusive.
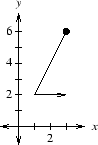
The figure above illustrates the ambiguous C or L symbol discussed earlier, this time with a coordinate grid drawn in. The two strokes of this symbol move from points (3,6) to (1,2) and then to (3,2). Thus this symbol would be represented in the input file by the following line.
2 3 6 1 2 3 2
Output
For each word presented in handin.txt as a sequence of symbols, a line should be written to the output file handout.txt containing the unique dictionary word that this sequence of symbols represents. The output words must be entirely in upper case, and must be presented in the order in which the corresponding sequences of symbols are presented in handin.txt.
Sample symbols.txt
A UD B URLRL C LR I D L DR #
Sample dict.txt
AIL BIC BILL CAB ILL LAB #
Sample handin.txt
3 5 1 1 2 4 4 3 3 2 4 0 2 1 1 2 5 3 1 2 3 6 1 2 3 2 4 5 1 1 2 4 4 3 3 2 4 0 2 1 1 2 5 3 1 2 3 6 1 2 3 2 2 3 6 1 2 3 2 0
Sample handout.txt
BIC BILL
Scoring
For each set of input files, let n be the number of words in handin.txt that your program is asked to recognise. If your program correctly recognises r of these words, it shall be awarded r/n of the available marks for that particular set of input files.
Privacy
statement
© Australian Mathematics Trust 2001-2024
Page generated: 25 April 2024, 9:05am AEST